Auch diesen Sommer finden wieder jährliche Revisionsarbeiten statt, daher bleiben die Lesesäle am Standort Heldenplatz und in allen Sammlungen von Freitag, 25. Juli bis Dienstag, 5. August 2025 geschlossen.
Aufgrund der Abschaltung des Bestellsystems können von Donnerstag, 24. Juli 2025, 16 Uhr bis Dienstag, 5. August 2025, 16 Uhr keine Medienbestellungen angenommen werden. Ab Mittwoch, 6. August 2025 gelten dann wieder die regulären Öffnungszeiten.
Der Studiensaal der Albertina ist von 15. Juli bis 15. August geschlossen. Während dieser Zeit (ausgenommen 25. Juli bis 5. August) werden bestellte Medien des Albertinabestandes zweimal wöchentlich (Montag und Donnerstag) in die Lesesäle der Nationalbibliothek am Heldenplatz transportiert und können dort verwendet werden.
Aufgrund einer Veranstaltung bleibt der Prunksaal am 4. August 2025 ganztägig geschlossen.
Autor: Mag. Andreas Predikaka
Die Österreichische Nationalbibliothek archiviert seit über zehn Jahren möglichst umfassend das österreichische Web in ihrem Webarchiv Österreich. Diese Webinhalte werden durch Crawler nach bestimmten Vorgaben gesammelt.[1]
Dabei verhält sich ein Crawler ähnlich einem Browser, der eine ausgewählte Webadresse aus dem Web abruft. Beide Programme kommunizieren über das "Hypertext Transfer Protocol" (HTTP) mit einem Webserver, von dem sie über einen "Uniform Resource Locator" (URL) eine "HyperText Markup Language"-Datei (HTML-Datei) laden.[2]
Diese Textdatei beinhaltet alle Anweisungen für den Browser, wie die angeforderte Webseite am Bildschirm angezeigt werden soll. Weitere zur Darstellung notwendige Dateien sind darin referenziert und werden ebenso geladen. Aus diesen technischen Web-Objekten erzeugt der Browser, eine für die BenutzerInnen sichtbare Oberfläche. Die zweite technische Ebene kann bei Bedarf im Browser eingeblendet werden.

Die Dateien, die der Browser für die Darstellung der Webseite abruft, werden auch vom Crawler geladen und gespeichert. Während der Browser auf die nächste Interaktion der BenutzerInnen wartet, folgt ein Crawler automatisch allen Links in dieser und jeder weiteren HTML-Datei. Das passiert so lange, bis bestimmte vorher definierte Grenzen erreicht sind (Objektanzahl, Speichermenge, Crawltiefe). Alle dabei gesammelten Web-Objekte werden in Archivdateien mit den dazugehörigen Metadaten des Crawls gespeichert.
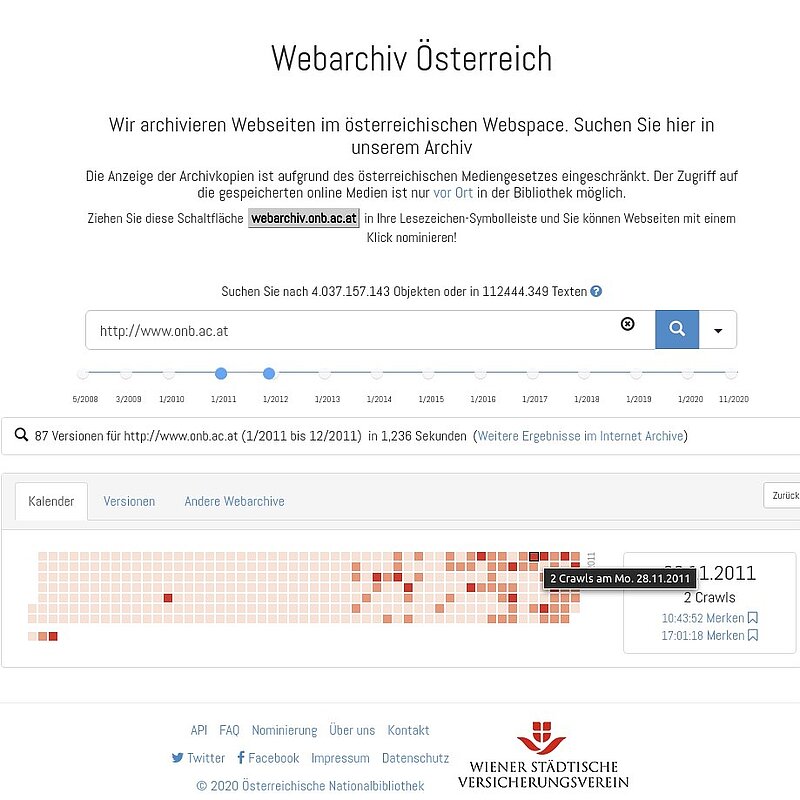
Im Webarchiv Österreich befinden sich über eine halbe Million dieser Archivdateien mit Milliarden von gecrawlten Web-Objekten, die mit einer URL und einem sekundengenauen Zeitstempel exakt identifiziert werden können. So kann man durch eine Art Zeitmaschine für das Web Zugriff auf das archivierte Web bekommen. Auf Basis aller URLs und der jeweiligen Zeitstempel, können alle vorhanden Zeitschnitte einer Webseite wieder rekonstruiert werden. Die bekannteste Zeitmaschine, die auf diese Weise eine Reise in die Vergangenheit des Webs ermöglicht, ist die sogenannte Wayback-Machine[3], die vom Internet Archive stammt und von der Österreichischen Nationalbibliothek und vielen anderen internationalen Webarchiven verwendet wird. Nach Eingabe einer Webadresse wird den BenutzerInnen eine Seite mit den einzelnen chronologisch geordneten Zeitschnitten dieser Webadresse angezeigt.
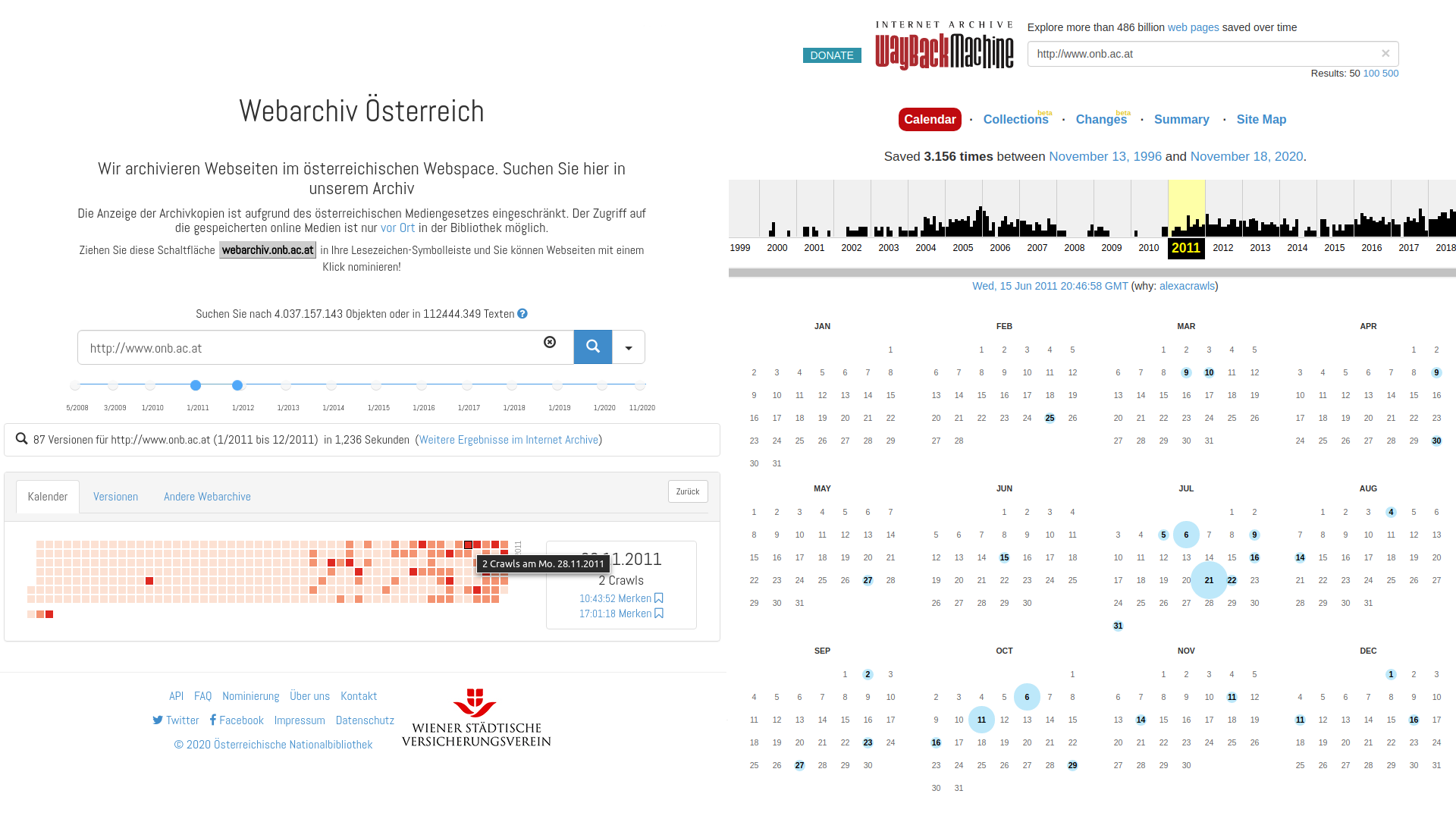
Wird ein bestimmter Zeitschnitt ausgewählt, wird diese gespeicherte Version aus dem Webarchiv mit den notwendigen referenzierten Dateien, in der zeitlich nähesten Version geladen und im Browser dargestellt. Um eine weitere Navigation im archivierten Web möglich zu machen, werden in jeder geladenen HTML-Datei alle Referenzen um eine zeitliche Komponente erweitert. Öffnen BenutzerInnen im Webarchiv eine Seite zu einem bestimmten Zeitschnitt und folgen im Browser einem Link, so wird ausgehend vom Zeitstempel der Ausgangsseite, der nächst liegende Zeitschnitt der verlinkten Seite aus dem Webarchiv geladen und angezeigt.
Nur selten wird eine verlinkte Seite den gleichen sekundengenauen Zeitstempel besitzen, da während eines Crawlvorganges nie alle Web-Objekte zeitgleich abgerufen und gespeichert werden können. Daher kann nicht gewährleistet werden, ob sich eine Webseite während des Crawls verändert hat oder nicht. Theoretisch wäre ein "Einfrieren" des Onlinewebs für die Dauer des Crawlvorganges die einzige Lösung. Praktisch lässt sich das höchstens für einzelne Webseiten durchführen. Um festzustellen, ob sich eine Webseite innerhalb eines Zeitraumes verändert hat, müsste sie zweimal hintereinander gecrawlt und daraufhin beide Archivversionen miteinander verglichen werden. Weisen beiden Versionen keine Unterschiede auf, handelt es sich um einen kohärenten Crawl.[4]
Durch die Architektur und die Dynamik des Webs ist es "niemals nachvollziehbar, ob, wann und wo das Web aktualisiert wurde"[5]. Für eine archivierte Webseite könnte es ein Original geben, aber in den meisten Fällen wird es nicht mehr vorhanden sein. Zudem besteht beim Crawlen von komplexen Webseiten immer die Gefahr eines Informationsverlustes, wenn ein Crawler nicht dieselben Fähigkeiten eines Browsers besitzt. Wie bei einem nicht kohärenten Crawl, entstehen dabei archivierte Webseiten, die so nie existiert haben. Demnach wird das archivierte Web in seiner Rekonstruktion im Webarchiv sozusagen „wiedergeboren“, es wird als ein "reborn digital medium"[6] bezeichnet.
BenutzerInnen von Webarchiven müssen sich bewusst sein, dass trotz der enormen verfügbaren Datenmengen, immer wieder Lücken und Inkonsistenzen bei der Anzeige von archivierten Webseiten auftreten können. Das Wissen über die komplexe Struktur des Webs ist hilfreich beim Erkennen, wie nahe die Rekonstruktion einer Webseite dem nicht mehr vorhandenen Original gekommen ist.
Die Österreichische Nationalbibliothek bedankt sich sehr herzlich beim Wiener Städtischen Versicherungsverein für die Unterstützung des Webarchivs Österreich.
Über den Autor: Mag. Andreas Predikaka ist technisch Verantwortlicher des Webarchivs Österreich an der Österreichischen Nationalbibliothek.
[1] Vgl. : Predikaka, Andreas (2020): "Wie das österreichische Web im Archiv landet", [online] https://www.onb.ac.at/mehr/blogs/detail/wie-das-oesterreichische-web-im-archiv-landet-3 [08.08.2023]
[2] Diese drei technischen Komponenten charakterisieren das Web. Vgl. Brügger, Niels (2018): The Archived Web. Doing History in the Digital Age, Cambridge London: The MIT Press, 23
[3] Benannt nach der Zeitmaschine WABAC, mit der die Hauptcharaktere der 1960er Zeichentrickserie "The Adventures of Rocky and Bullwinkle and Friends" durch die Geschichte reisen. [Online] https://youtu.be/6V7M4AfTOrw?t=205 , [24.11.2020]
[4] Vgl. Spaniol, Marc et. al.: Data Quality in Web Archiving, [online] https://web.archive.org/web/20201119235216/https://www.researchgate.net/profile/Marc_Spaniol/publication/221023143_Data_Quality_in_Web_Archiving/links/58764c5808ae8fce492dcd75/Data-Quality-in-Web-Archiving.pdf [24.11.2020]
[5] Brügger 2018: 87
[6] "digitized - born digital - reborn digital media". Vgl. Brügger 2018: 5f