Auch diesen Sommer finden wieder jährliche Revisionsarbeiten statt, daher bleiben die Lesesäle am Standort Heldenplatz und in allen Sammlungen von Freitag, 25. Juli bis Dienstag, 5. August 2025 geschlossen.
Aufgrund der Abschaltung des Bestellsystems können von Donnerstag, 24. Juli 2025, 16 Uhr bis Dienstag, 5. August 2025, 16 Uhr keine Medienbestellungen angenommen werden. Ab Mittwoch, 6. August 2025 gelten dann wieder die regulären Öffnungszeiten.
Der Studiensaal der Albertina ist von 15. Juli bis 15. August geschlossen. Während dieser Zeit (ausgenommen 25. Juli bis 5. August) werden bestellte Medien des Albertinabestandes zweimal wöchentlich (Montag und Donnerstag) in die Lesesäle der Nationalbibliothek am Heldenplatz transportiert und können dort verwendet werden.
Aufgrund einer Veranstaltung bleibt der Prunksaal am 4. August 2025 ganztägig geschlossen.

Das Web ist Teil des kulturellen Erbes eines Landes und muss für nachfolgende Generationen erhalten werden. Seit 2009 kümmert sich die Österreichische Nationalbibliothek mit einer kombinierten Crawling-Strategie darum, den österreichischen Web Content zu archivieren.
Autor: Mag. Andreas Predikaka
Das Web, das seit über 30 Jahren immer stärker Geschehen und Wissen unserer Welt abbildet, erweist sich als äußerst flüchtiges Medium. Unterschiedlichen Studien zufolge haben Webseiten eine durchschnittliche Lebensdauer von 44 bis 100 Tagen[1]. Es gibt Webseiten, die bleiben Jahre unverändert, andere ändern sich mehrmals täglich, Social-Media-Seiten wiederum liefern gar bei jedem Aufruf einen anderen Inhalt.
Dass Webinhalte, genauso wie Handschriften, Bücher oder Zeitungen zum kulturellen Erbe eines Landes gehören und deshalb schützenswert sind, wird immer bekannter, wie die steigenden Zugriffszahlen auf das Webarchiv Österreich zeigen.
Seit am 1. März 2009 in Österreich die Mediengesetznovelle[2] in Kraft getreten ist, kümmert sich die Österreichische Nationalbibliothek um die Archivierung des österreichischen Web Contents. Dabei bewegt sich ein spezielles Programm, ein sogenannter Crawler, durch das österreichische Web und legt eine Kopie der österreichischen Webseiten im Archiv ab. Ausgehend von einer Liste mit Adressen von Webseiten (Seeds) ruft der Crawler die Inhalte der einzelnen Seeds ab, speichert sie, extrahiert alle verfügbaren Links und folgt diesen nach einer Reihe definierter Regeln, die beispielsweise Crawl-Tiefe, Objektanzahl oder Speichermenge bestimmen.
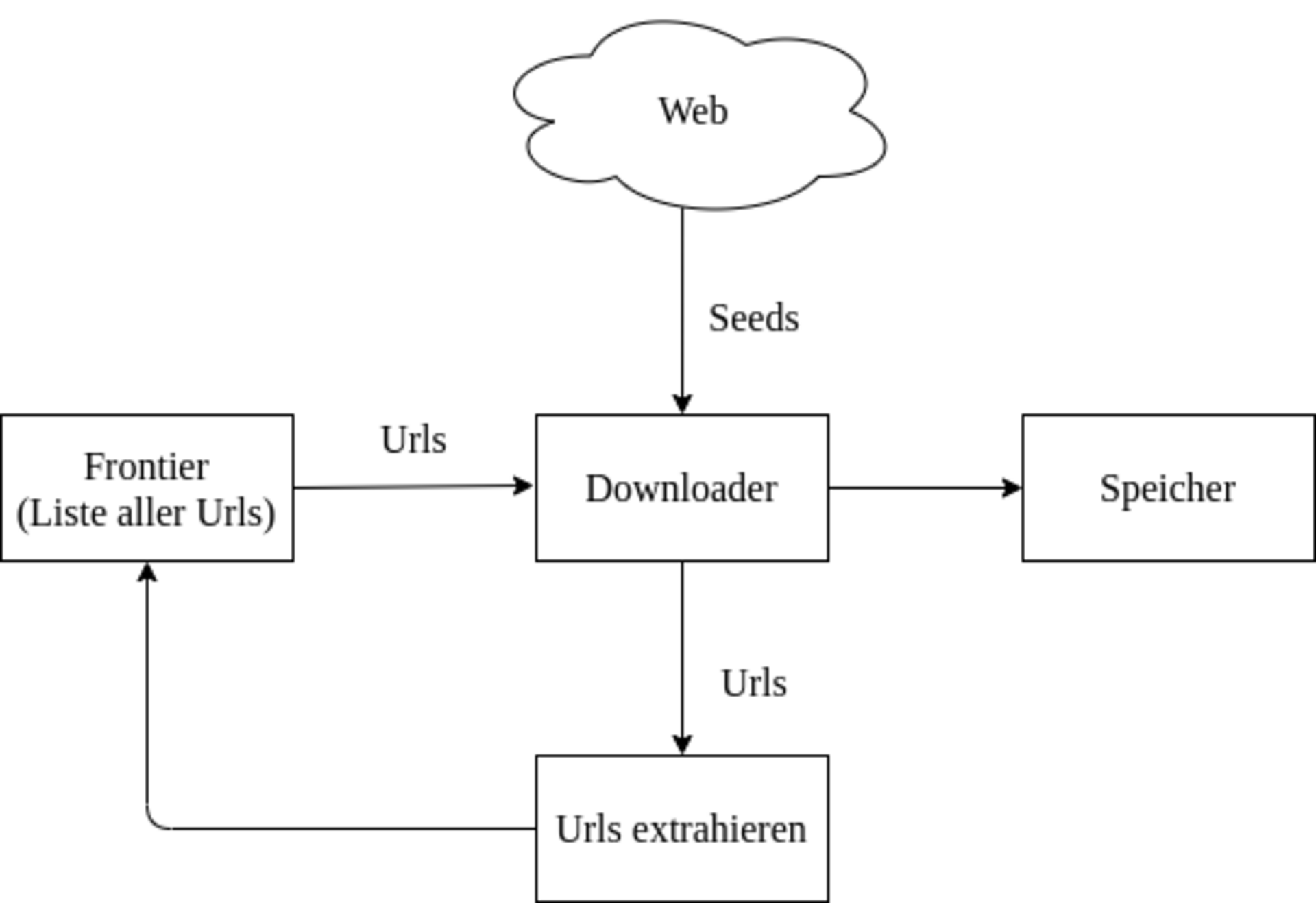
Auf diese Weise wird versucht, einen signifikanten Teil des nationalen Webspaces zu sammeln und zu archivieren. Diese komplexe Aufgabe der Datensammlung wird durch die Kombination verschiedener Sammlungsmethoden bewerkstelligt. Beim sogenannten Domain Crawl werden alle Domains unterschiedlicher Top-Level-Domains anhand von Gesamtlisten der jeweiligen Registrierungsstelle als Ausgangsseeds für einen Crawl verwendet. Zusätzlich zur österreichischen .at Domain, inklusive aller Second-Level-Domains (.or.at, co.at, ac.at, gv.at, priv.at), werden seit Einführung von generischen Domains auch die kompletten Domainlisten der Top-Level-Domain .wien und .tirol verwendet. Ergänzt werden diese Listen mit Adressen von Webseiten österreichischer MedieninhaberInnen, die über andere Top-Level-Domains erreichbar sind. Da es dafür keine Verzeichnisse gibt, werden solche Adressen laufend von WebkuratorInnen für den Domain Crawl gesammelt. Auch LeserInnen sind aufgerufen dem Webarchiv Österreich auf https://webarchiv.onb.ac.at Webseiten mit Österreichbezug zur Archivierung zu übermitteln.
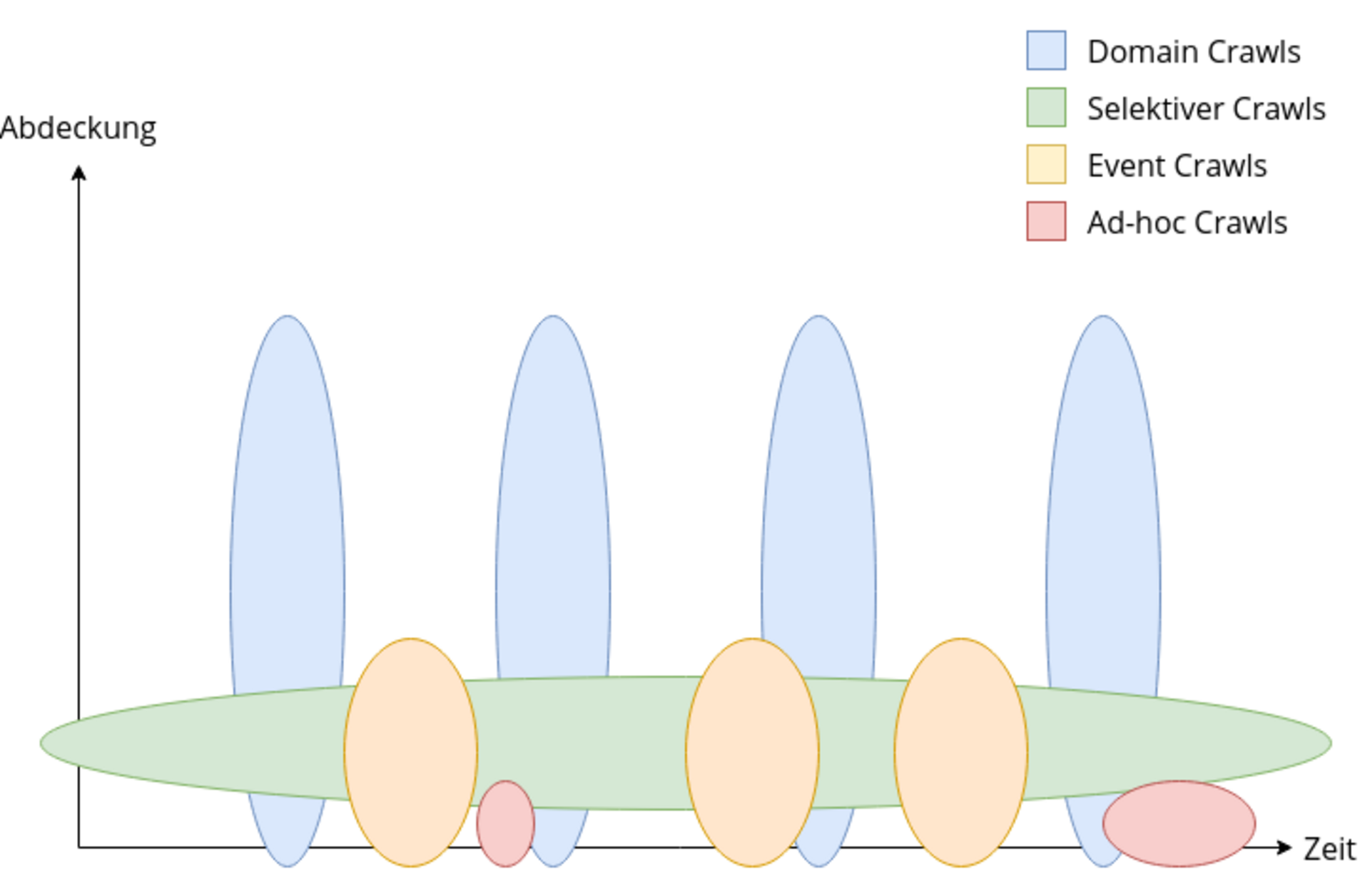
Um mit dem verfügbaren Speicherbudget eines Domain Crawls einen möglichst repräsentativen Ausschnitt aller Domains zu sammeln, wird ein Domain Crawl mehrstufig durchgeführt. In der ersten Stufe werden alle Domains bis zu einer bestimmten Speichergrenze gecrawlt. Die Domains, die diese Grenze überschritten haben, werden in der nächsten Stufe bis zu einer weiteren größeren Speichergrenze gecrawlt. Danach verbleiben nur mehr Domains mit sehr viel Content, die in einem abschließenden Crawl komplett gespeichert werden. Auch wenn aus Kapazitätsgründen das Webarchiv Österreich bisher immer zweistufig crawlte (Speichergrenzen von 10 und 100 Megabytes), so konnten in den ersten vier Domain Crawls dennoch über 95 Prozent aller Domains vollständig archiviert werden[3]. Wenngleich der Gesetzgeber der Österreichischen Nationalbibliothek erlaubt bis zu vier Domain Crawls im Jahr durchzuführen, so kann aufgrund der benötigten großen Speichermengen derzeit nur ein Domain Crawl pro Jahr stattfinden.
Aufgrund der geringen Frequenz von Domain Crawls würden besonders bei Webseiten, die häufigen Änderungen unterliegen, zahlreiche Inhalte für die Webarchivierung verloren gehen. Aus diesem Grund werden zu bestimmten Themenbereichen wie Medien, Politik, Wissenschaft und Behörden von WebkuratorInnen wichtige Webseiten ausgewählt. Für diese Seiten werden geeignete Crawl-Intervalle festgelegt und regelmäßig Selektive Crawls durchgeführt. So werden z.B. Nachrichten-Webseiten und Seiten politscher Parteien täglich gespeichert, um die wesentlichen Inhalte zu archivieren.
Eine Sonderform des Selektiven Crawls ist der Event Crawl, bei dem Inhalte zu bestimmten Ereignissen archiviert werden. Zahlreiche Webseiten stehen oft nur für den Zeitraum eines Ereignisses zur Verfügung und verschwinden danach sehr rasch. Unter Berücksichtigung der geschätzten durchschnittlichen Lebensdauer einer Webseite besteht jedenfalls das Risiko, dass Seiten bis zum nächsten geplanten Domain Crawl bereits wieder verschwunden sind. Klassische Themen für Event Crawls sind z.B. Veranstaltungen oder Wahlen. In der Regel werden mit dem Event Crawl geplante Ereignisse abgedeckt, bei denen die Dauer bekannt ist und ausgehend davon eine bestimmte Crawl-Dauer definiert werden kann. Exakt planbar waren zum Beispiel die Crawls zu den Olympische Winterspielen 2010 und 2014 oder der Eurovision Song Contest 2015, der in Österreich stattfand. Die Crawl-Dauer wurde dabei über die Länge der Veranstaltung inklusive einer definierten Vor- und Nachlaufzeit bestimmt. Crawls zu Wahlen beginnen mit der Zulassung der wahlwerbenden Personen oder Parteien und enden mit dem Beginn der Amtstätigkeit der gewählten Person oder Regierung. Die Dauer dieser Crawls ist somit nicht präzise vorhersehbar, so dauerte der Crawl zur Bundespräsidentenwahl 2016 aufgrund mehrerer Wahlwiederholungen ungewöhnlich lange.
Es kann aber auch sein, dass es plötzlich notwendig wird, Webseiten zu einem bestimmten Thema zu archivieren. Diese spontanen Event Crawls werden auch Ad-hoc Crawls genannt. In so einem Fall ist es natürlich nicht absehbar, wie lange ein Crawl dauern wird. Die 2015 plötzlich auftretende Flüchtlingsbewegung bewirkte einen Event Crawl, der erst nach einigen Jahren beendet wurde. Das bekannte Ibiza Video löste einen Event Crawl zu einer Regierungskrise aus, der erst nach mehreren Folgeereignissen (Entlassung der Regierung, Übergangsregierung, Neuwahlen und Regierungsbildung) beendet werden konnte. In so einem Fall werden natürlich während des Events laufend Webseiten hinzugefügt und die Crawl-Intervalle nach deren Änderungsverhalten angepasst. Seit März dieses Jahres läuft der bisher größte Event Crawl zur Corona-Krise. Ein Ereignis, das in alle Bereiche der Gesellschaft eingriff und sich im gesamten österreichischen Web widerspiegelt. Ein Ende dieses Crawls ist noch lange nicht absehbar und laufend werden neue Seiten dafür ausgewählt und gespeichert. In diesem Fall bekommt der Domain Crawl für 2020 einen ganz besonderen Stellenwert, da so eine sehr große Anzahl an Seiten mit Corona-Bezug automatisch ins Archiv wandern werden, die ansonsten kuratorisch nicht berücksichtigt hätten werden können.
Eine laufende vollständige Sammlung des österreichischen Webs ist mit den derzeitigen Ressourcen nicht realistisch, es wird aber versucht mit der eben beschrieben Crawling-Strategie und bewusstem Mut zur Lücke ein möglichst umfangreiches und aussagekräftiges Abbild des österreichischen Webspaces für zukünftige Generationen zu sichern. Bis heute konnte so ein Datenbestand von über 145 Terabytes (entspricht über 3,8 Milliarden digitalen Objekten) aufgebaut werden.
Das Webarchiv Österreich wird bereits seit vielen Jahren vom Wiener Städtische Versicherungsverein unterstützt, wofür wir uns sehr herzlich bedanken.
Über den Autor: Mag. Andreas Predikaka ist technisch Verantwortlicher des Webarchivs Österreich an der Österreichischen Nationalbibliothek.
[1] Taylor, Nicholas (2011): The Average Lifespan of a Webpage, [online] https://web.archive.org/save/https://blogs.loc.gov/thesignal/2011/11/the-average-lifespan-of-a-webpage/ [27.08.2020]
[2] Änderung des Mediengesetzes: BGBl. I Nr. 8/2009, [online] https://web.archive.org/web/20200827142329/https://www.ris.bka.gv.at/Dokumente/BgblAuth/BGBLA_2009_I_8/BGBLA_2009_I_8.html [27.08.2020]
[3] Mayr, Michaela / Andreas Predikaka (2016): Nationale Grenzen im World Wide Web - Erfahrungen bei der Webarchivierung in der Österreichischen Nationalbibliothek. In: BIBLIOTHEK Forschung und Praxis 40/1, 90-95. 90–95, [online] https://doi.org/10.1515/bfp-2016-0007 [27.08.2020]