Auch diesen Sommer finden wieder jährliche Revisionsarbeiten statt, daher bleiben die Lesesäle am Standort Heldenplatz und in allen Sammlungen von Freitag, 25. Juli bis Dienstag, 5. August 2025 geschlossen.
Aufgrund der Abschaltung des Bestellsystems können von Donnerstag, 24. Juli 2025, 16 Uhr bis Dienstag, 5. August 2025, 16 Uhr keine Medienbestellungen angenommen werden. Ab Mittwoch, 6. August 2025 gelten dann wieder die regulären Öffnungszeiten.
Der Studiensaal der Albertina ist von 15. Juli bis 15. August geschlossen. Während dieser Zeit (ausgenommen 25. Juli bis 5. August) werden bestellte Medien des Albertinabestandes zweimal wöchentlich (Montag und Donnerstag) in die Lesesäle der Nationalbibliothek am Heldenplatz transportiert und können dort verwendet werden.
Ab 1. August 2025 öffnet der Prunksaal bereits um 9 Uhr.
Aufgrund einer Veranstaltung bleibt der Prunksaal am 4. August 2025 ganztägig geschlossen.

Um die Speichermenge bei der Webarchivierung zu reduzieren, wird neben dem Vorgang der Datenkomprimierung auch der Prozess der Datendeduplizierung eingesetzt. Dabei werden Duplikate erkannt und nur die Referenz auf das Originalobjekt gespeichert.
Autor: Andreas Predikaka
Durch das schnelle und stetige Anwachsen des österreichischen Webs benötigt das Webarchiv Österreich laufend weiteren Speicherplatz, um ein signifikantes Abbild des heimischen Webspaces für die Nachwelt bewahren zu können. Dabei gilt es, sorgsam mit dem bereitgestellten Speicher umzugehen und diesen optimal zu nutzen. Dafür sind zwei Vorgänge für das Webarchiv mittlerweile gängige Praxis und unverzichtbar geworden: Datenkomprimierung und Datendeduplizierung.
Wie in vielen anderen Bereichen kommt auch in der Webarchivierung Datenkompression zum Einsatz. Im Webarchiv Österreich wird jedes gecrawlte Web-Objekt vor dem Speichern verlustfrei mit dem quelloffenen gzip1 Programm komprimiert und in einer Archiv-Datei gespeichert. Das Programm verwendet den gemeinfreien Deflate-Algorithmus2 zur verlustfreien Datenkompression.
Abhängig vom jeweiligen Dateityp können dabei unterschiedliche Kompressionsraten erzielt werden. Textdateien, wie die im Web üblichen HTML-Dateien, können mit einer sehr hohen Rate komprimiert werden. Bei Bilddateien ist das hingegen oft nicht der Fall, da diese für die Verwendung im Web meist schon komprimiert wurden.
Im Webarchiv Österreich wird zurzeit für alle gecrawlten Web-Objekte (aktuell 138 Terabytes) eine Komprimierungsrate von 1,7 erreicht, was eine Speicherplatzersparnis von 42 Prozent bedeutet. Der auf den Festplatten benötigte Speicher beträgt dadurch nur mehr knapp 80 Terabytes.
Für alle erzeugten Metadaten (aktuell 19,5 Terabytes), die aus gut komprimierbaren Textdateien bestehen, kann sogar eine Komprimierungsrate von knapp 11 erreicht werden, womit eine Speicherplatzersparnis von knapp 91 Prozent erzielt wird. Nur mehr knapp zwei Terabytes an Metadaten werden dafür im Speichersystem benötigt.
Ausgewählte Seiten aus dem Bereich Medien und Politik werden im Webarchiv Österreich seit über zehn Jahren in eigenen Kollektionen gespeichert. Da bei diesen Seiten eine hohe Änderungsfrequenz zu erwarten ist, werden diese, immer unter Berücksichtigung des aktuellen Speicherbudgets, mindestens einmal pro Tag gecrawlt. Dabei werden unvermeidbar immer wieder die gleichen Daten, wie z.B. Parteilogos oder Bilder von Personen gespeichert, was zu einer Vielzahl an Redundanzen führt und das vorhandene Speicherbudget schneller verbrauchen lässt.
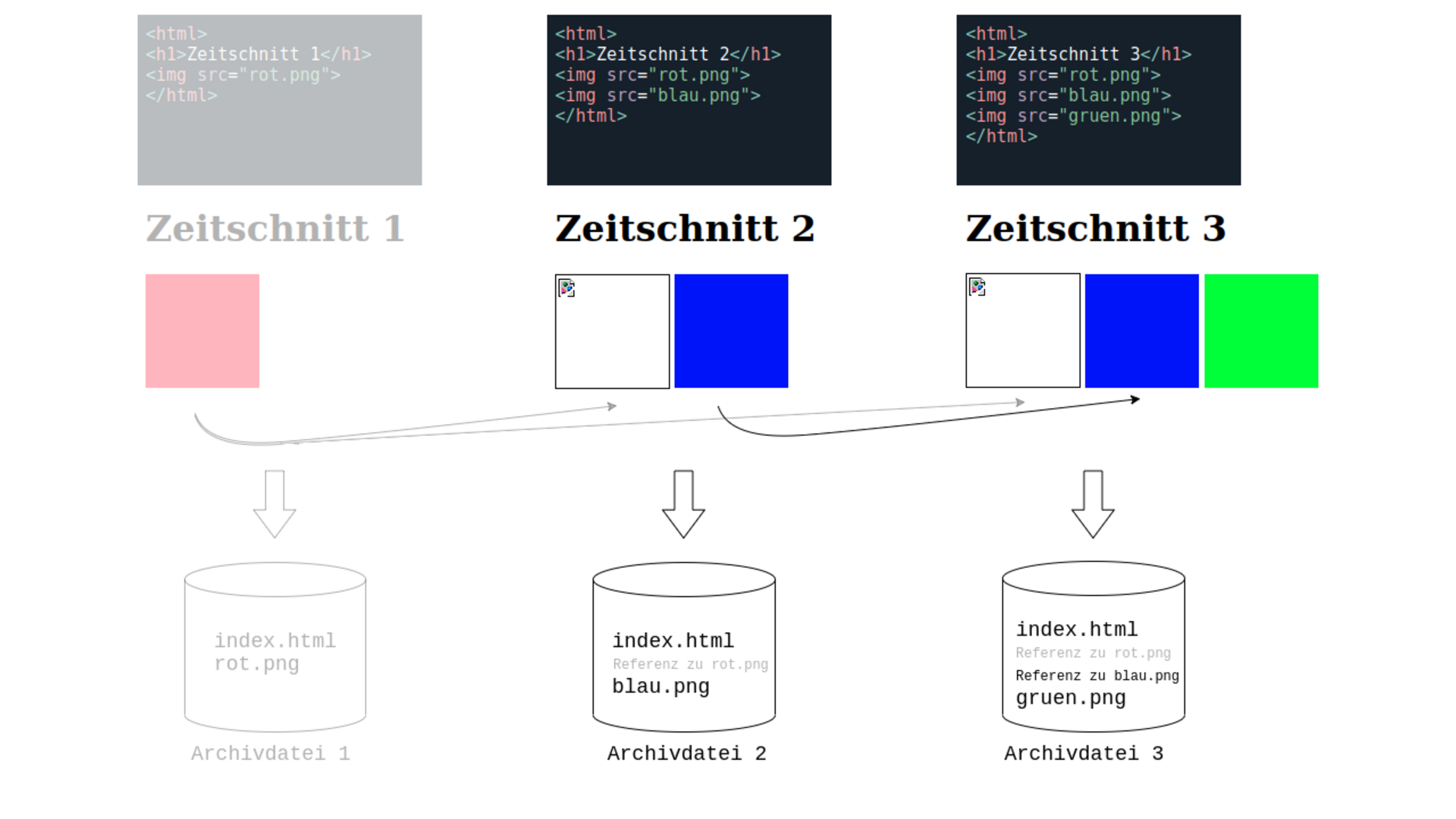
Um diese Redundanzen teilweise einzuschränken, verwendet das Webarchiv die Methode der Deduplizierung. Sie ermöglicht es, einen großen Teil der binären Objekte (Bilder, Videos, Dokumente, Skripte, usw.) dieser regelmäßig gecrawlten Seiten nur als Referenz zum Erstauftreten des jeweiligen Objektes zu speichern. Wie funktioniert das?
Für jedes Objekt, das im Webarchiv gespeichert werden soll, wird ein Hashwert3 erzeugt, der das Objekt eindeutig identifiziert. Beim erstmaligen Auftreten eines Objektes wird dieses archiviert und der dafür errechnete Hashwert bekommt die exakte Position des Objektes im Webarchiv hinterlegt. Dadurch kann beim wiederholten Crawlen eines bereits existierenden Objektes diese Position anstelle der Daten des Objektes gespeichert werden.
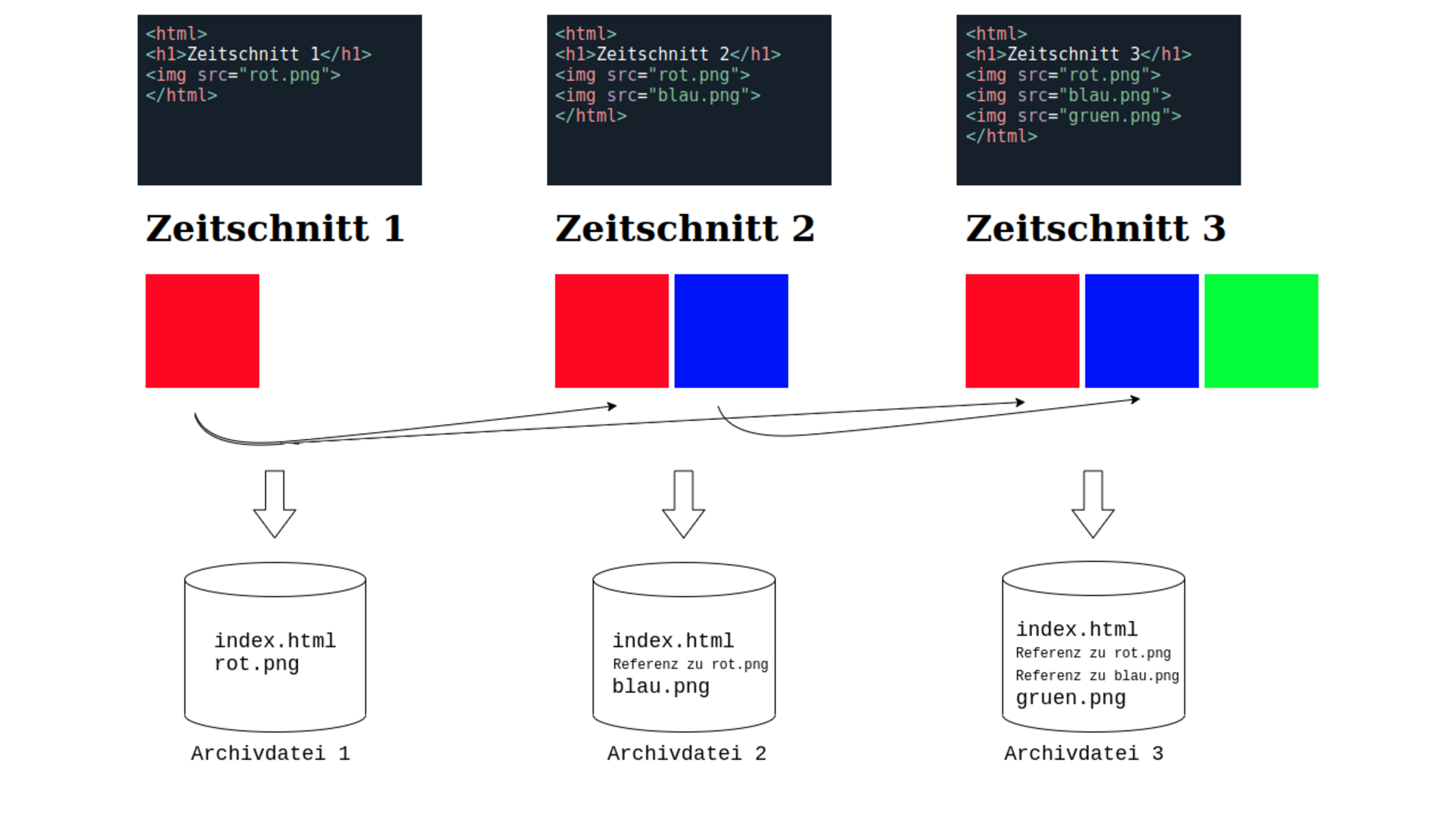
Ist ein auf diese Weise dedupliziertes Objekt Bestandteil einer archivierten Webseite, wird beim Aufruf dieser Seite in der Waybackmachine das Objekt von der referenzierten Position im Webarchiv geladen und angezeigt.4
HTML-Dateien werden von der Deduplizierung ausgenommen, weil bei diesen Dateien in regelmäßigen Crawls die häufigsten Änderungen zu erwarten sind, wodurch sie nicht mehr für eine Deduplizierung in Frage kämen. Für unveränderte HTML-Dateien wäre eine Speicherplatzersparnis minimal, weil ihre Textinhalte bereits sehr gut komprimiert werden können.
Deduplizierung ist aber auch zu einem gewissen Grad risikobehaftet. Sollte es im Webarchiv zu Datenverlusten kommen und wären Objekte, die referenziert wurden, davon betroffen, könnten die Rückverweise nicht mehr aufgelöst werden und der Datenverlust würde sich um die Anzahl der Referenzen multiplizieren. Deshalb wird bei regelmäßigen Crawls auch immer wieder ein sogenannter "Clean Crawl" durchgeführt, der auf Deduplizierung verzichtet und dadurch wieder neue Ausgangsobjekte für neue Referenzen weiterer Deduplikationen bildet. Auf diese Weise streuen sich die Originalobjekte im Webarchiv, was den Schaden bei eventuellen Datenverlusten reduzieren kann.
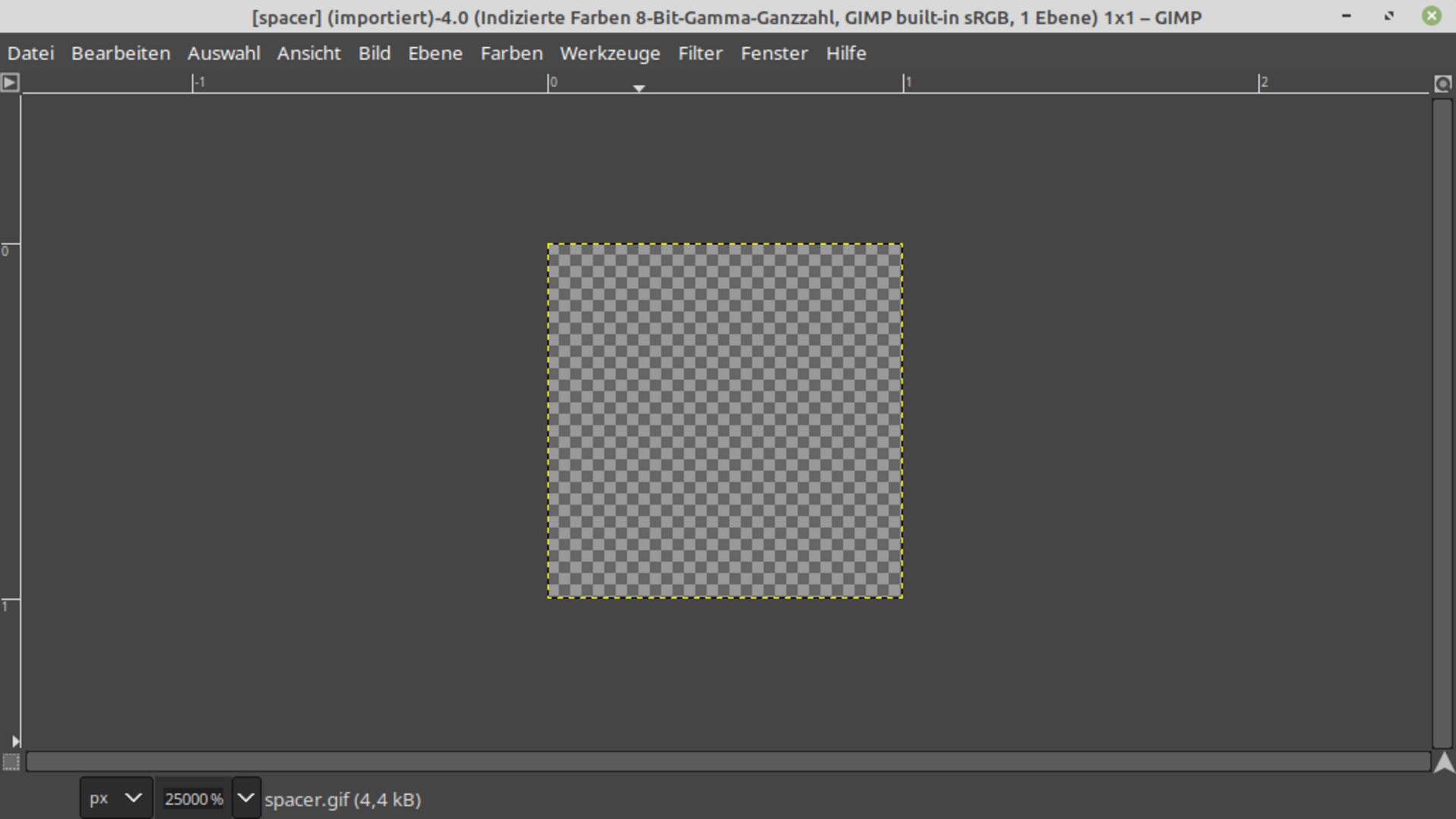
Zu den am häufigsten deduplizierten Objekten im Webarchiv Österreich zählt eine 1x1 Pixel große transparente GIF-Datei mit 43 Bytes, die vor allem auf älteren archivierten Webseiten verwendet wurde, um das Layout dieser Seiten zu beeinflussen. Über 2,3 Millionen Mal wurde dieses Objekt auf unterschiedlichen Webseiten dedupliziert. Für diese kleine Datei ist der Speicherplatzgewinn aufgrund der nur unwesentlich kleineren Information über die Referenz aber sehr gering.
Ganz anders beim Objekt mit der meisten Speicherplatzersparnis, einem Video über eine Pressekonferenz5, das zwar nur 1225-mal dedupliziert wurde, aber dadurch knapp 170 Gigabytes an Speicher einsparen konnte.
Gesamt wurden im Webarchiv Österreich bis jetzt 882 Millionen Objekte mit einer Gesamtgröße von über 59 Terabytes dedupliziert, was 30 Prozent der unkomprimierten Speichergröße des Archivs ausmacht.
Die Österreichische Nationalbibliothek bedankt sich sehr herzlich beim Wiener Städtische Versicherungsverein für die Unterstützung des Webarchivs Österreich.
Über den Autor: Mag. Andreas Predikaka ist technisch Verantwortlicher des Webarchivs Österreich an der Österreichischen Nationalbibliothek.
1 [online] https://de.wikipedia.org/wiki/Gzip , [22.06.2022]
2 [online] https://de.wikipedia.org/wiki/Deflate , [22.06.2022]
3 [online] https://de.wikipedia.org/wiki/Hashfunktion , [22.06.2022]
4 Vgl.: Predikaka, Andreas (2020): "Wie das archivierte österreichische Web wieder auf den Bildschirm kommt", [online] https://www.onb.ac.at/mehr/blogs/detail/wie-das-archivierte-oesterreichische-web-wieder-auf-den-bildschirm-kommt-3 , [08.08.2023]
5 Alle Zeitschnitte dieses Videos können im Webarchiv Österreich angezeigt werden: https://webarchiv.onb.ac.at/?q=http://www.wien-konkret.at/fileadmin/content/Politik/Wahlrecht/video-pk-faires-wahlrecht.flv