Eine der bekannten Strategien, um Inhalte des österreichischen Webs zu sammeln, ist die Durchführung eines Domain Crawls. Wie wird dieser durchgeführt und was ist dabei zu beachten?
Autor: Andreas Predikaka
Seit 1. März 2009 ist die Österreichische Nationalbibliothek gesetzlich ermächtigt das nationale Web zu sammeln. Während WebkuratorInnen für bestimmte Themenbereiche wie Medien, Politik, usw. laufend relevante, sammlungswürdige Webseiten auswählen und diese in geeigneten Speicherintervallen im Rahmen von Selektiven Crawls für die nachfolgenden Generationen archivieren lassen, werden zusätzlich regelmäßig alle bekannten Domains des österreichischen Webs automatisiert gespeichert. Diese Art der Archivierung wird „Domain Crawl“ genannt und dient dazu ein einmaliges, oberflächliches Abbild des gesamten nationalen Webs zu schaffen. Paragraph 43b des Mediengesetzes definiert den österreichischen Webspace wie folgt:
"§ 43b. (1) Die Österreichische Nationalbibliothek ist höchstens viermal jährlich zur generellen automatisierten Sammlung von Medieninhalten periodischer elektronischer Medien [...] berechtigt, die öffentlich zugänglich und 1. unter einer ".at"-Domain abrufbar sind oder 2. einen inhaltlichen Bezug zu Österreich aufweisen."1
Vor allem Punkt zwei bedeutet in der Praxis einen laufenden kuratorischen Aufwand, um Domains mit Österreich-Bezug ausfindig zu machen.2 Aus diesem Grund ist es notwendig die Ausgangsadressen für jeden neuen Domain Crawl an aktuelle Gegebenheiten und Entwicklungen anzupassen, um dadurch mehr nationale Inhalte crawlen und den potentiellen Verlust wichtiger Inhalte verringern zu können.
Domainnamen-Listen
Viele relevante Domainnamen für diese Art des Crawls melden uns WebkuratorInnen und LeserInnen3 oder sind Ergebnis von halbautomatischen Suchverfahren. Aber der Großteil der Namen wird über Listen unterschiedlicher Domain-Registrierungsstellen bezogen.
Ursprünglich wurden die ersten .at Domain-Registrierungen noch von der Universität Wien verwaltet, aber die hohe Nachfrage an Domainnamen machte es notwendig die Domainverwaltung als Dienstleistungsunternehmen zu etablieren, was im Jahr 2000 in Form der nic.at geschah, die seither die .at Domain administriert.4 Die Verwaltung des Namensraumes für akademische Einrichtungen .ac.at verblieb bei der Universität Wien. Neben der Namen der .at Domain, ist nic.at auch noch für die Verwaltung der für kommerziell orientierte Unternehmen vorgesehenen Subdomain .co.at, und für den Namensbereich .or.at zuständig. Die wenig bekannte Subdomain .priv.at wurde 1995 geschaffen, um eine kostengünstige Domain-Zone für Privatpersonen in Österreich zu schaffen. Die Verwaltung dieser Subdomain obliegt zur Zeit dem Verein VIBE!AT.5 Der weithin bekannte Namensraum .gv.at ist für Bundes- und Landesbehörden vorgesehen und wird dementsprechend vom Bundeskanzleramt verwaltet.
In Folge der Einführung der neuen generischen Domains6 im Jahre 2013 wurden die Namen der beiden Top Level Domains .wien und .tirol aufgrund des eindeutigen inhaltlichen Bezuges zu Österreich vollständig für den Domain Crawl übernommen. Für deren Verwaltung sind die punkt.wien GmbH7 bzw. punkt Tirol GmbH8 verantwortlich. Alle Namen dieser beiden Top-Level-Domains werden direkt von der Internet Corporation for Assigned Names and Numbers (ICANN)9 bezogen.
All diese gesammelten Domainnamen dienen als Datenbasis für den jährlich durchzuführenden Domain Crawl. Während der erste Crawl 2009 knapp 900.000 Domains umfasste, fanden 2022 bereits knapp 1,5 Millionen Domainnamen Verwendung.
Webseiten werden mit einem Crawler im Webarchiv gespeichert. Dabei startet ein Crawler bei einer Ausgangsadresse, folgt jedem Verweis auf der Seite und speichert alle Inhalte bis ein definiertes Limit erreicht ist.10
Ein Domainname ist jedoch keine Webadresse. Es fehlt noch der Name des Webservers, auf dem die Webseite gehostet wird. Da diese Information für die gesammelten Domainnamen nicht bekannt ist, wird der übliche Hostname www in Verbindung mit dem Kürzel des Protokolls http jedem Domainnamen vorangestellt, um so eine für den Crawler gültige Ausgangsadresse zu erzeugen. Aus dem Domainnamen onb.ac.at wird beispielsweise die Adresse http://www.onb.ac.at. In den meisten Fällen kann so die Startseite des wichtigsten Webserver der Domain erreicht werden. Sind für eine Domain weitere Hostnamen bekannt, werden diese in einem manuellen Prozess als weitere Ausgangsadressen erfasst (z.B. http://webarchiv.onb.ac.at , http://labs.onb.ac.at usw.).
Crawl-Management
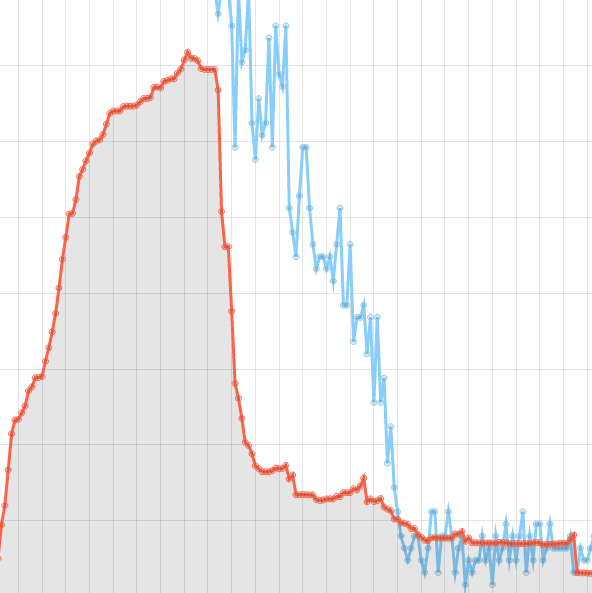
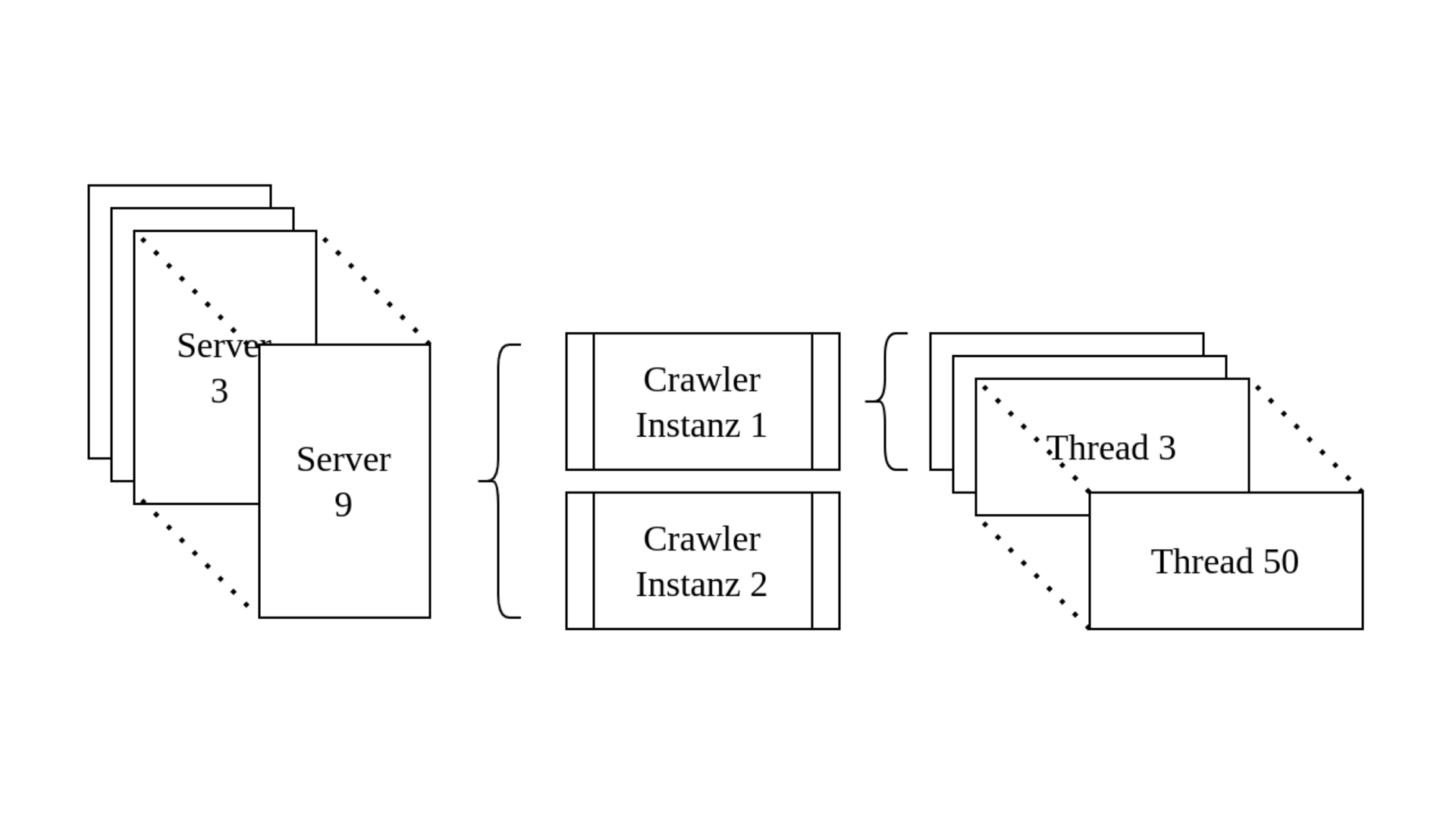
Das Archivieren von mehr als einer Million Startadressen kann nicht mit einem Crawler auf einmal durchgeführt werden. Die Ausgangsadressen müssen portionsweise an eine Vielzahl von Crawler-Instanzen übergeben werden. Die Aufteilung aller Adressen auf viele Instanzen übernimmt das Software-System NetarchiveSuite, das im Rahmen des dänischen Webarchivierungsprojektes von der Dänischen Königlichen Bibliothek entwickelt und 2007 als Open Source Software zur Verfügung gestellt wurde. Inzwischen wird das System von einem Zusammenschluss von der KB Dänemark, der Französischen, Spanischen, Schwedischen und Österreichischen Nationalbibliothek weiterentwickelt.11 In der aktuellen Infrastruktur der Österreichischen Nationalbibliothek stehen für den Domain Crawl neun Server mit je zwei Crawler-Instanzen zu je 50 Threads zur Verfügung. Auf diese Weise können theoretisch Objekte von bis zu 900 Domains gleichzeitig angefordert und gespeichert werden. Jeder Crawler wird mit maximal 2500 Ausgangsadressen gestartet.
Die Anzahl der eingesetzten Server und Instanzen muss natürlich immer im Einklang der zugesicherten Bandbreite des Internets stehen, ansonsten könnten Serveranfragen nicht mehr schnell genug abgeholt werden, was zu unvollständigen Datenübertragungen und dadurch zu korrupten Downloaddaten führen könnte. Alle Crawler-Instanzen laufen für alle Domains mit denselben Einstellungen und speichern alle Objekte, die nach der Ausgangsadresse auf der Ausgangsdomain zu erreichen sind. Um zu verhindern, dass bei Erreichen des Gesamtspeicherlimits große Domains komplett und viele kleine Domains noch gar nicht gecrawlt wurden, wird ein Domain Crawl stufenweise durchgeführt. Alle Domains werden am Beginn bis zu einer Gesamtspeichermenge von zehn MB gecrawlt, was für 95 Prozent aller Domains bereits reicht, um sie vollständig zu archivieren. Mit dem aktuellen Speicherbudget ist es möglich alle noch nicht vollständig gecrawlten Domains, noch einmal bis zu einer neuen Grenze von 100 MB zu crawlen. Bei genügend verfügbaren Speicher könnte man mit dieser Vorgangsweise einen vollständigen Crawl der gesamten nationalen Domainlandschaft durchführen, was aus Kapazitätsgründen bisher noch nie stattfinden hat können.
Die Crawler sind so konfiguriert, dass sie sich wie im Web surfende Menschen verhalten. Nach dem Laden aller referenzierten Objekte einer Seite bzw. nach dem Erreichen einer definierten Gesamtspeichermenge macht der Crawler eine kurze Pause um einerseits den Zielserver zu entlasten und andererseits den verwendeten Crawler-Thread für Anfragen an die nächste wartende Domain freizugeben. Auch auf die Antwortzeiten der Server wird Rücksicht genommen. Benötigt ein Server für eine Antwort länger, wird der Zeitabstand bis zur nächsten Anfrage größer. Am Beginn eines sogenannten Crawl-Jobs ist eine Instanz mit der gesamten verfügbaren Thread-Anzahl ausgelastet. Die Crawl-Dauer eines Jobs wird einerseits durch die Anzahl der Threads pro Crawler-Instanz und andererseits durch die Menge der Ausgangsadressen und der maximalen Speichergrenze pro Domain bestimmt. Da alle Server unterschiedliche Antwortzeiten haben, werden nicht alle Domains eines Jobs gleich schnell gecrawlt. Das hat zur Folge, dass ein Job immer dieselbe Verlaufskurve beschreibt.
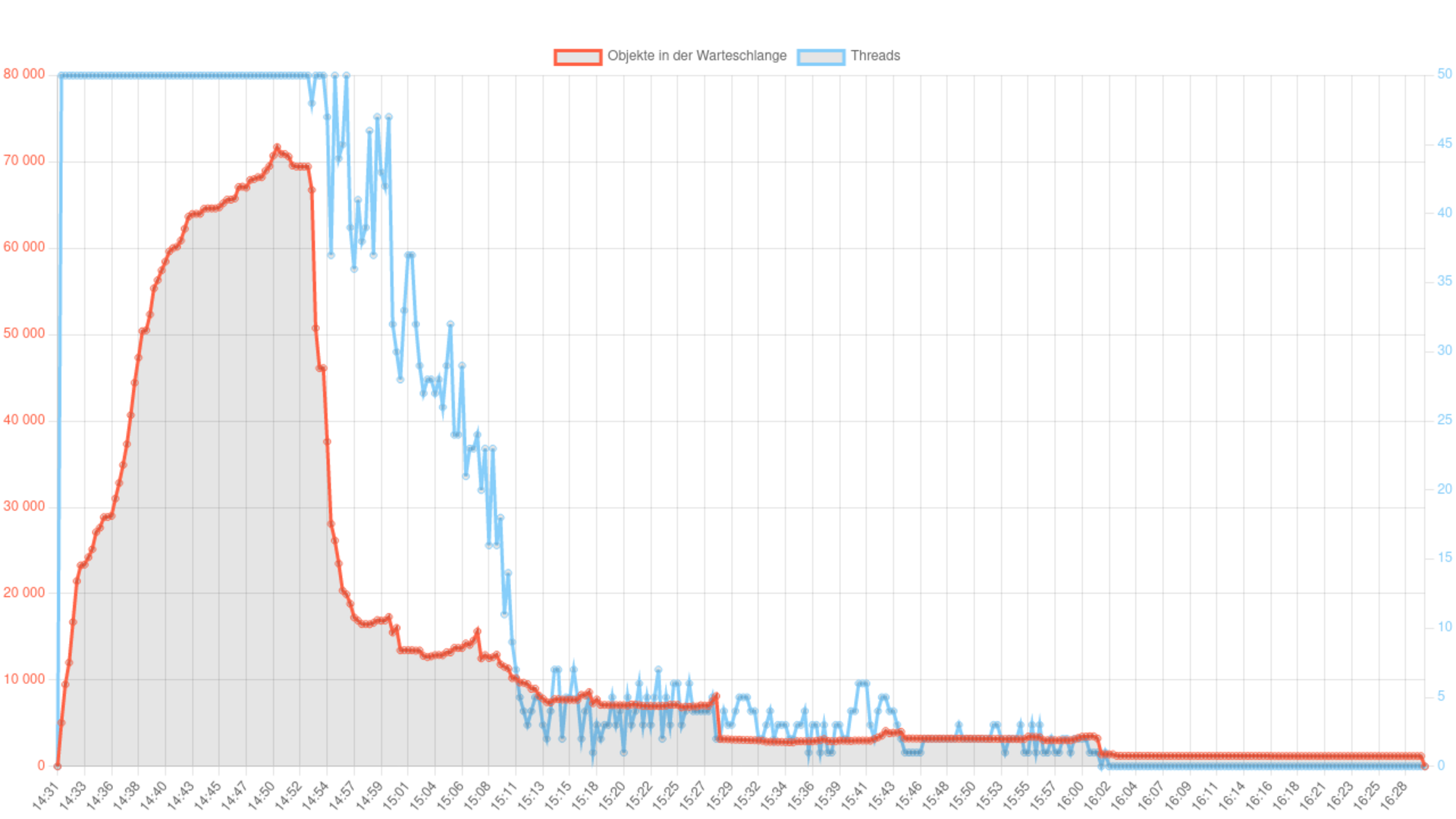
Alle Threads werden eine bestimmte Zeit vollständig benutzt und nach einer gewissen Zeit sind immer weniger in Verwendung. Am Ende wird nur mehr ein Thread für wenige noch nicht fertig gecrawlte Domains benötigt. Sobald die letzte Domain aus dem Job die Abbruchbedingung erreicht hat, ist der Crawl-Job beendet und eine weitere Crawler-Instanz mit neuen Ausgangsadressen wird automatisch gestartet. Bleibt ein Crawl-Job im Vergleich zu anderen Jobs auffällig lange aktiv und wird nicht beendet, so ist der Crawler höchstwahrscheinlich in einer sogenannten Crawler-Trap gefangen, aus der er befreit werden muss.
Auch wenn ein Domain Crawl mit so wenig Interaktion wie möglich laufen sollte, kommt irgendwann der Zeitpunkt, an dem es notwendig ist manuell einzugreifen. Oft gelangt ein Crawler auf Webseiten in einen Kalender, bei dem über Verweise Tage, Wochen, Monate oder Jahre verändert werden können. Jedes neue Kalenderblatt generiert eine neue Seite mit neuen Links. Der Crawler bleibt in diesem Kalender "gefangen" und kann sich erst selbst befreien, wenn vordefinierte Abbruchbedingungen erreicht werden, was sehr lange dauern kann. Daher sollte zu diesem Zeitpunkt der Crawl-Engineer manuell eingreifen und die betroffenen Links aus der Crawl-Warteschlange entfernen. Die gespeicherten Daten aus dem Kalender wären zwar valide, aber die meisten wahrscheinlich nicht sehr relevant.
Es gibt aber auch Werkzeuge, sogenannte "Honey-Pots" 12, die von Webadministrator*innen eingesetzt werden, um bösartige, datensammelnde Crawler ins Leere oder Endlose laufen zu lassen. Das passiert häufig bei Missachtung von Ausschlussregeln, die auf jedem Webserver in der sogenannten robots.txt13 oder in Meta-Tags14 auf HTML-Seiten definiert werden können. Diese Regeln dienen den Betreiber*innen von Webseiten dazu, gewisse Bereiche ihrer Seite für Crawler zu sperren bzw. nur bestimmte Crawler zuzulassen. Diese Anweisungen sind allgemein anerkannt und Crawler sollten sich daranhalten, jedoch kann ein Zugriff auf damit "gesperrte" Inhalte ohne weitere Absicherungsmaßnahmen nicht verhindert werden.
Da die Webarchivierung im gesetzlichen Auftrag betrieben wird und gegenüber diesen Anweisungen Vorrang hat, können solche Fallen für Crawler der Österreichische Nationalbibliothek zum Problem werden. Gelangt ein Crawler in einen Bereich, den er eigentlich nicht betreten sollte, könnte dort ein Honey-Pot warten, der ihn so lange ins Unendliche laufen lassen würde, bis er erst durch eine Abbruchbedingung oder durch manuelle Intervention befreit würde. Leider mit dem bitteren Beigeschmack, dass dabei Daten von zufällig sinnfrei aneinandergereihten Wörtern ins Webarchiv gelangen könnten.

Für diese Fälle sind sehr knappe Speicherbudgets sogar ein Segen, weil in unentdeckten Fällen, nicht zu viel Speicherplatz verloren geht (aktuell pro Domain und Durchlauf max. zehn bzw. 100 MB).
Mit aktuellem Stand sind bisher 55 Prozent (über 120 TB) aller gesammelten Daten des österreichischen Webs über Domain Crawls ins Archiv gelangt. Auch wenn der Vorgang eines Domain Crawls nach sorgfältiger Vorbereitung automatisch ablaufen kann, ist man gut beraten, wenn man dennoch ein Auge auf ihn behält.
Die Österreichische Nationalbibliothek bedankt sich sehr herzlich beim Wiener Städtische Versicherungsverein für die Unterstützung des Webarchivs Österreich.
Über den Autor: Mag. Andreas Predikaka ist technisch Verantwortlicher des Webarchivs Österreich an der Österreichischen Nationalbibliothek.
1 Änderung des Mediengesetzes: BGBl. I Nr. 8/2009, § 43: https://web.archive.org/web/20151028093639/https://www.ris.bka.gv.at/Dokumente/BgblAuth/BGBLA_2009_I_8/BGBLA_2009_I_8.html [25.11.2022]
2 Vgl. die Kriterien zur Einstufung von sogenannten Austriaca: Mayr, Michaela / Andreas Predikaka (2016): Nationale Grenzen im World Wide Web - Erfahrungen bei der Webarchivierung in der Österreichischen Nationalbibliothek. In: BIBLIOTHEK Forschung und Praxis 40/1, 91, [online] doi.org/10.1515/bfp-2016-0007 [25.11.2022]
3 Über Webformular oder Bookmarklet auf [online] https://webarchiv.onb.ac.at/#nominierung [25.11.2022]
4 [online] https://web.archive.org/web/20221017080623/https://www.nic.at/de/das-unternehmen/firmengeschichte [25.11.2022]
5 [online] https://web.archive.org/web/20221017102027/http://www.vibe.at [25.11.2022]
6 [online] https://de.wikipedia.org/wiki/Neue_Top-Level-Domains [25.11.2022]
7 [online] https://web.archive.org/web/20221120160048/https://www.nic.wien/de/wien/projekt-wien [25.11.2022]
8 [online] https://web.archive.org/web/20221120160154/http://www.nic.tirol/ueber-uns/ueber-punkt-tirol/ [25.11.2022]
9 [online] https://de.wikipedia.org/wiki/Internet_Corporation_for_Assigned_Names_and_Numbers [25.11.2022]
10 Vgl.: Predikaka, Andreas (2020): "Wie das archivierte österreichische Web im Archiv landet", [online] https://www.onb.ac.at/mehr/blogs/detail/wie-das-oesterreichische-web-im-archiv-landet-3 [08.08.2023]
11 [online] https://github.com/netarchivesuite/netarchivesuite [25.11.2022]
12 z.B.: [online] https://www.projecthoneypot.org [25.11.2022]
13 [online] https://de.wikipedia.org/wiki/Robots_Exclusion_Standard [25.11.2022]
14 [online] https://de.wikipedia.org/wiki/Meta-Element#Anweisungen_f%C3%BCr_Webcrawler [25.11.2022]
Aufgrund einer Veranstaltung ist der Prunksaal am 24. April 2024 ab 14 Uhr geschlossen.